This is the third video in a series discussing cluster computing with the Raspberry Pi, and I'm posting the video + transcript to my blog so you can follow along even if you don't enjoy sitting through a video :)
In the first episode, I talked about how and why I build Raspberry Pi clusters like the Raspberry Pi Dramble. In the second episode, I spoke about how to put everything together in a Turing Pi cluster and get the Raspberry Pi Compute Modules ready to boot.
In this episode, I'm going to show you how to find and connect to all the Raspberry Pis, then how to install Kubernetes on the Turing Pi cluster.
Find your Pis
When I flashed all the Compute Modules with Hypriot OS, I set a unique hostname for each Pi, like master, worker-01, and worker-02.
I didn't just do that for fun; it helps me find them on my network, when I boot them up and plug the Turing Pi into the network. It also helps me associate the Pi's IP addresses with their hostnames, which may come in handy later.
After you plug in the Turing Pi, you have to wait a few minutes for all the Pis to fully boot. The first boot can take a while, because Hypriot or even Raspbian has to do a bit of housekeeping the first time it boots up. Usually, you'll know the Pis are booted when the red activity LED next to each board is mostly 'off' instead of 'on'. Once booted, assuming you have the Turing Pi plugged into your network, you can go to another Mac or Linux computer on the same network and run the following command:
nmap -sn 10.0.100.1/24 | grep 'turing\|worker'
In this command, I'm calling the nmap utility, which is a utility used for Network Mapping. I'm telling it to look for any devices with IP addresses in the same range as my main network. For my network, the network ID and subnet mask is 10.0.100.1/24. Your own network is probably different, like 192.168.0.1/24. You can find out your own ID and mask using ifconfig on a Mac, or ip a on most Linux machines.
If you run this command without the grep, then it will return a list of all the devices on your network, including the seven Pis installed in the Turing Pi! Because I piped the output through grep, though, I could easily filter the list to just get the worker Pis and the master pi.
I can grab their IP addresses from the list, noting which IP corresponds to which hostname, for example: worker-03 is 10.0.100.197, and turing-master is 10.0.100.163.
I can then use ssh to log into each server, using either their hostname or their IP addresses, and verify I can connect successfully. You will probably have to accept the new host key for each server as you connect to it. Type yes and press enter to accept the host key. The host key is used so your computer can verify it's connecting to the same server every time, and not an imposter that's trying to steal your data.
Once you connect to one of the Pi servers, you can explore if you want, or type exit to get back to the command line and test the connection to the next server.
Once you confirm all the servers are running and able to be accessed, it's finally time to install Kubernetes!
Introduction to Kubernetes
But let's not get ahead of ourselves! We have all these Pis running, but I'd forgive you if you're a little like the kid in the Incredibles:
Just like with a single Pi, there are seemingly infinite possibilities with a cluster of Raspberry Pis. But we need some software to make it easier to run applications on the cluster without having to log into each Pi all the time.
And one bit of clustering software that's become extremely popular is Kubernetes.
But... what the heck is Kubernetes. Well, I put together this little animation for a presentation I did last year at Flyover Camp in Kansas City, Missouri.
At the very basic level, you have applications you want to run, like a web CMS, a database, a chat system, search, and redis caching. And then you have a bunch of servers—in this case, Raspberry Pis—that you want to run things on:
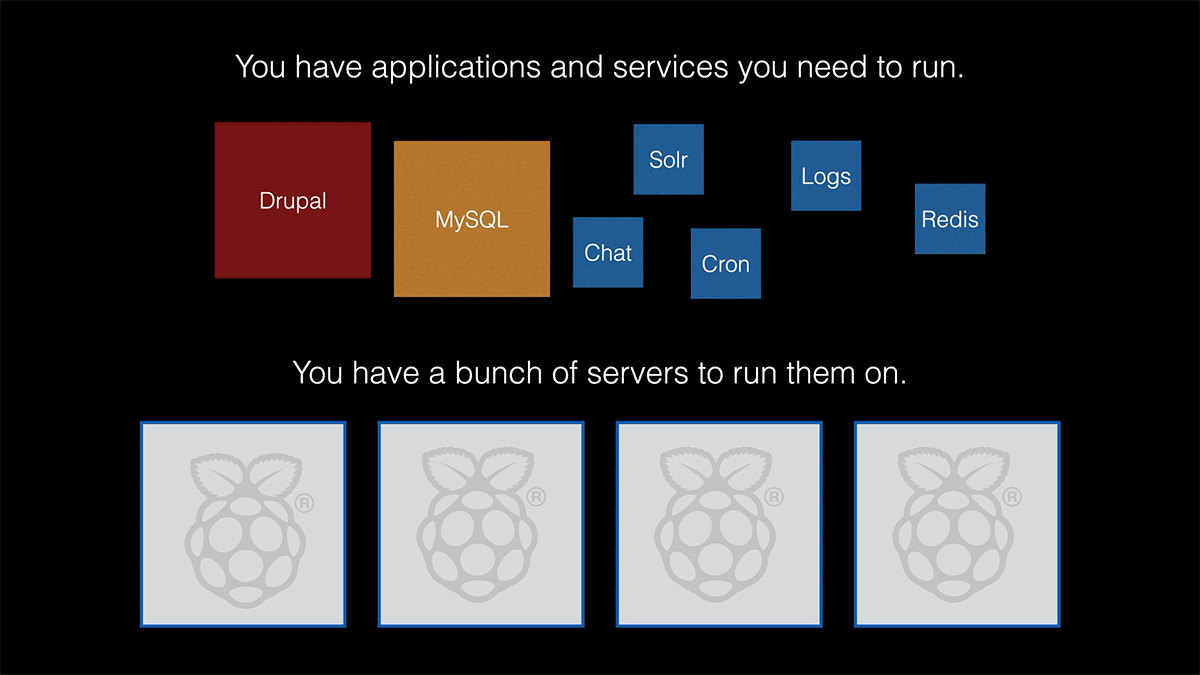
Kubernetes takes those applications, and gets them running on your servers, and then keeps them running on your servers, even when there's trouble.
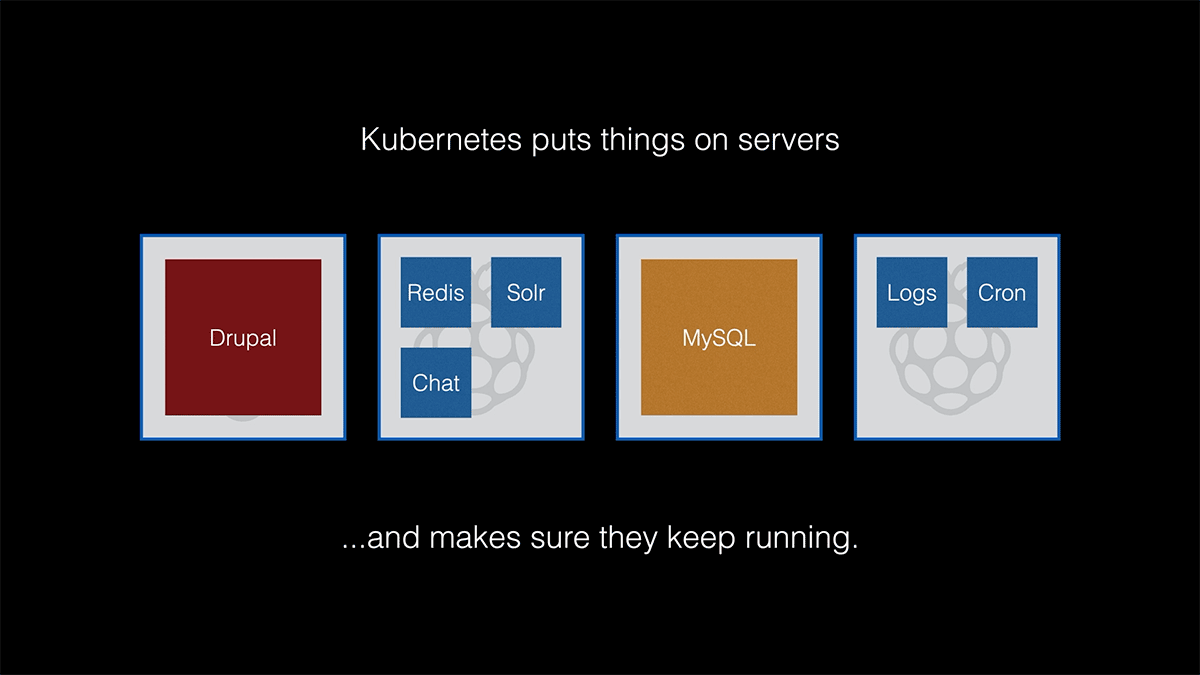
That's about the most basic description possible, because Kubernetes can do a whole lot more, and can be very complicated for large scale clustering. But for basic needs, Kubernetes isn't as daunting as you might think.
Picking the right flavor of Kubernetes
So let's install Kubernetes!
Simple, right? We'll just go to the Kubernetes website, download it, and install it. Easy peasy, all done.
Well, not so fast. As with all things in life, installing Kubernetes can be a little bit complicated, mainly because there are many different flavors of Kubernetes you can install. Each one has its own benefits and drawbacks, just like with different Raspberry Pi OSes like Raspbian and HypriotOS.
There are large scale, enterprise Kubernetes flavors, like OpenShift or the full Kubernetes stack. And there are more lightweight, trimmed down Kubernetes flavors, like K3s by Rancher, or MicroK8s, by Canonical. And these are only a few of the many options.
The full Kubernetes installation runs on a Raspberry Pi—but just barely. I've run it on my clusters, and found that sometimes Kubernetes would start failing on Pis that only had one gigabyte of memory, like the Compute Modules do. And all the services that run with a full Kubernetes installation take a toll on a mobile CPU like the one in the Raspberry Pi.
A distribution of Kubernetes like OpenShift has a ton of great features for usability, but it comes at a cost: at a minimum, you need three master servers running with 16 GB of RAM each! Not gonna happen with our little Pis.
MicroK8s and K3s both run on lighter weight hardware, but K3s focuses more on the extreme end of 'lightweight', and is easier to set up with more advanced configurations for HA, or 'high availability'.
And then when you finally choose a distribution of Kubernetes, you realize there are dozens of ways to actually install it. You could use kubeadm on the command line to set up a cluster, or you could use the AWS CLI to build an Amazon EKS cluster. You could install a cluster with Terraform or Ansible, or run something like Kubespray!
If it seems like there's a lotta similar options when you research things with Kubernetes, well, it's because there are. There are often too many ways, in my opinion, to do something with Kubernetes, and it can be overwhelming! Just look at all the tools highlighted by the Cloud Native Computing Foundation (which maintains Kubernetes) in the Cloud Native Landscape.
In our case, I'm sticking with K3s. It runs great on Raspberry Pis and installs really fast.
So let's go the K3s website and work on getting it set up.
Installing K3s on the Turing Pi
Some people might go and run some random shell script off the Internet to install K3s. But we're a little more advanced than that. Instead of blindly running a complex bash script, I like to know what's happening.
I also hate doing things more than once. So I use Ansible, which is the easiest way to maintain automated processes to manage my servers.
And lucky for me, Rancher has a fully functional Ansible playbook that builds a Kubernetes cluster with K3s!
You just need to download or clone the k3s-ansible repository, modify the playbook inventory, and run it:
- Download using the 'Download ZIP' link on GitHub on https://github.com/rancher/k3s-ansible
- Edit the Ansible inventory file
inventory/hosts.ini, and replace the examples with the IPs or hostnames of your master and nodes. This file describes the K3s masters and nodes to Ansible as it installs K3s. - Edit the
inventory/group_vars/all.ymlfile and change theansible_usertopirate. - Run
ansible-playbook site.yml -i inventory/hosts.iniand wait.
To connect to the cluster, once it's built, you need to grab the kubectl configuration from the master:
scp pirate@turing-master:~/.kube/config ~/.kube/config-turing-pi
Make sure you have kubectl installed on your computer (you can install it following these directions).
Then set the KUBECONFIG environment variable, and start running kubectl commands:
export KUBECONFIG=~/.kube/config-turing-pi
kubectl get nodes
You should get a list of all the Pi servers; if you do, congratulations! Your cluster is up and running, ready to run workloads!
Resetting K3s
If you mess anything up in your Kubernetes cluster, and want to start fresh, the K3s Ansible playbook includes a reset playbook, that you can run from the same directory. Just run:
ansible-playbook reset.yml -i inventory/hosts.ini
I like to make a habit of resetting the entire cluster from time to time, just to make sure I've automated every application deployment into the cluster, but that's a topic for another day!
Shutting down the Turing Pi Cluster
Instead of just unplugging the Turing Pi, it's best to safely shut down all the Raspberry Pis. Instead of logging into each Pi and running the shutdown command, you can use Ansible, since it already knows how to connect to all the Pis. Just run this command:
ansible all -i inventory/hosts.ini -a "shutdown now" -b
Ansible will report failure for each server since the server shuts down and Ansible loses the connection, but you should see all the Pis power off after a minute or so. Now it's safe to unplug the Turing Pi.
Conclusion
So now we have a running Kubernetes cluster. That's great! But again, we come back to the question, what can we do with it?
Well, for that, you'll have to wait for the next episode, where I'll deploy some applications to the cluster and show you some of the amazing things you can do with the Turing Pi cluster running K3s!
Make sure you subscribe to my YouTube channel so you don't miss the next episode.
If there's anything I missed or questions you have about the Turing Pi and clustering, please feel free to ask in the comments below.
Comments
Hi, Jeff, I am David from China, I have two Servers ( from Alibaba ), one in China, one in US, I already build the K3S cluster and it runs well for kubernetes-example: kubernetes-bootcamp. I want to use it to build a Drupal site, with 1 replicas (both Drupal and mysql, The mysql in China with Read/Write as master, and the mysql in US server with Read only as slave maybe) on each Node. How can I achieve this ? I can't use helm with the bitnami/drupal chart to do this (I am new for Kubernetes). Do you have any brief suggetions for me.
As the above goal accomponished, I want to use the DNS (www.dnspod.cn from China) to do the following DNS record for my Domain:
the DNS record for IP address in China's server for China region's users, and the IP address in US's server for Global users maybe.
So the user from China can visit the website from China's Server, and others can visit the website from the US's server.
Thanks for your time, wish to see more episodes about Drupal and K3S from you.
Are you using the 32-bit or 64-bit version of Hypriot?
Thnnks
Mike
There is currently no 64-bit version of HypriotOS available, and according to comments in this issue, it seems that may stay the case for a while.
Your videos have inspired me to invest in some Raspberry Pi4 x4 4Gb with official PoE HAT.
Everything seems to be setup, with ssh (key based) connecting to the Pis fine. Ansible seems to work okay for simple commands to, for example, check free memory.
However, every time I run the playbook for k3s, all seems to go well on all four of my Pis until this task:
Nothing happens beyond this point. Never moves on to another stage. Never returns to the command prompt. No error messages. Pis are still working fine (and can login to them from another terminal).
I've wiped the Pis and started again, and I've run the playbook from both a MacBook Pro and from a Ubuntu 20.04 desktop. Gets stuck on this both times.
I had a look at the details of the task, but as I've not got around to reading your books yet (I've bought both) I can't really make much sense of it and am not sure where to start looking. Any advice would be appreciated.
I have resolved. Tried several times, including running the installation manually on each pi.
Made the playbook work in the end by switching from hostnames (pik01.local, etc) to static ip addresses in the inventory file. Worked fine after this.
I'm just in the process of building my small cluster with four Raspberry Pi 4 (4GB) / Hypriot OS and wanted to give a heads up to my fellow travelers.
If, during the k3s-ansible installation, you get an error like:
a fix is to replace "- raspbian is true" with "- raspbian|bool == true" in the k3s-ansible/roles/raspbian/tasks/main.yml.
Thank you so much Jeff for explaining these complex topics in such clarity.
Just out of curiosity, can you run
ansible --versionand check what version of Ansible you're running? It could be that you're on a version older than maybe 2.8 or 2.9 and that is why the check is failing.I updated to ansible 2.9.10 before starting. Actually the problem was introduced with the https://github.com/rancher/k3s-ansible/commit/6534ecaa83a3a8b63efb7c5fb… PR (May 30, while your video was shot on May 19).
The check
"ansible_facts.lsb.description is match("[Rr]aspbian.*[Bb]uster")"
was replaced with
"raspi is true".
The PR comment is "Fix to make work on Raspbian64" which apparently broke something for the rest of us 32-bit-die-hards.
D'oh! It was working great prior to that; maybe open a new issue on the K3s-ansible repo? I left a comment here: https://github.com/rancher/k3s-ansible/commit/6534ecaa83a3a8b63efb7c5fb6d1583414a24244#r40439199.
Super new to all of this. i am in the k3s-ansible dir and when i put in the command ansible-playbook site.yml -i inventory/hosts.ini i get this error -bash: ansible-playbook: command not found. i am at a loss any help would be fantastic
Did you install kubectl?
Here is a slightly different nmap incantation that I find very useful:
nmap -sn 192.168.1.0/24 | grep -i rasp -B 2
This will print out every raspberry pi system on your network (assuming your network is 192.168.1.0/24) and tell you it's hostname and ip address. Each Pi will have three lines like this:
Nmap scan report for dharani (192.168.1.20)
Host is up (0.00018s latency).
MAC Address: DC:A6:32:XX:XX:XX (Raspberry Pi Trading)
So the above three lines correspond to one Pi named dharani with ip address 192.168.1.20 and MAC address DC:A6:32:XX:XX:XX (well, with the last three octets Xed out). The "-B 2" option for grep means "print out the line matches and the two lines BEFORE it".
Good evening Jeff, hope you are doing well!!
I am following your guide and ran into an issue, getting an error when running the playbook:
"The task includes an option with an undefined variable. The error was: 'k3s_version' is undefined\n\nThe error appears to be in '/etc/ansible/k3s-ansible/roles/download/tasks/main.yml': line 26, column 3, but may\nbe elsewhere in the file depending on the exact syntax problem.\n\nThe offending line appears to be:\n\n\n- name: Download k3s binary armhf\n ^ here\n"}
and line 26 is:
26 - name: Download k3s binary armhf
Not sure what its looking for here.
Thanks!!
Jeff
Hey Jeff, figured out my issue, to many hours at the keyboard.
Thanks,
Jeff
I'm seeing the same thing. What was the solution?
I tried replacing {{ k3s_version }} with version "v1.20.4+k3s1" (current version) and it did the same. Where is {{ k3s_version }} defined?
I found where it is set in group_var/all.yml and updated it to "v1.20.4+k3s1" but I'm still getting the failure.
fatal: [turing-master]: FAILED! => {"msg": "The task includes an option with an undefined variable. The error was: 'k3s_version' is undefined\n\nThe error appears to be in '/Users/*******/GitHub/k3s-ansible/roles/download/tasks/main.yml': line 26, column 3, but may\nbe elsewhere in the file depending on the exact syntax problem.\n\nThe offending line appears to be:\n\n\n- name: Download k3s binary armhf\n ^ here\n"}
Found my issue. You have to create a sub-folder /inventory/my-cluster/ (this is stated clearly in the directions - that I wasn't following correctly)
I was trying to run site.yml against hosts.ini and /* all.yml that I had created directly in the /inventory folder. Everything runs fine if you create a sub-folder and run against it. I couldn't find anything in the playbooks that might cause this but it's the only difference between failure and success.
Regards.
I have noticed that the versions you install of k3s from the script or or by hand node to node. The one in the script is less problematic but I don't know where to put the next variable.
export INSTALL_K3S_EXEC=" --no-deploy servicelb --no-deploy traefik"
When I do it by hand and then I want to install Metallib and Traefik. I get a lot of notice that there are many things deprecated. Because the k3s version is more advanced.
Tks
I'm trying to find a solution to exactly the same issue. I'd like to use Metallb and nginx, but can't find a place to put that variable to.
In case it helps someone, the right place is all.yml under inventory/my-cluster/group_vars. There is a following line:
extra_server_args: ""
I replaced it with this:
extra_server_args: "--disable servicelb --disable traefik --node-taint node-role.kubernetes.io/control-plane=true:NoSchedule"
Can you mention what emmc memory you used for your build.
would a bigger emmc have any impact at all?
Hey Jeff, appreciate you putting this together (just bought your book Ansible for DevOps, great stuff). I've built a pi cluster with 6 4Bs (8 GB memory). Your instructions worked for the Raspberry Pis; however, when trying to join a CentOS 8.3 agent it attaches to pi server but won't do work successfully or create a k3s server. I think the issues are related into some basic network or security setup. I've created an issue https://github.com/k3s-io/k3s/issues/3118 to hopefully help others. Curious if you have any thoughts from your experience. Thank you.
After taking all the steps in Episode 2 and it being done successfully I am now going to plug my Turing Pi in with all the modules in place. Do you put the that little plug thing back in it's original place -- the one you had to move when you were putting the Turing Pi into flash mode?
Also, when I plugged mine in it asked for a black-pearl login and password. I have no idea where to find that. What do I do ?
Thanks for help and feedback.
Nick
Hi Nick,
Hope you are not stuck here still, but the user name and password was listed in the user-data file which was covered in Jeff's video https://www.youtube.com/watch?v=xNndbfxMCLo timestamp: 11:41. However if you need it, the user name "pirate" and password is "hypriot"
Hi Jeff,
Great series and great material. I'm at a bit of a pickle. I've tried to follow all your instructions to the letter though now I'm utterly stuck.
when running the ansible-playbook site.yml -i inventory/hosts.ini I start getting into issues of connection. I get a "fatal: [ipaddress]: UNREACHABLE! => {"changed": false, "msg": "Failed to connect to the host via ssh: usern at ipaddress: Permission denied
However, when I manually attempt ssh for master and slaves/nodes alike there are no issues.
Do you have any suggestions to what might be going wrong here?
Great instructions. I have my first RPi4 cluster running with this help.
NOTE: I am using three RPi4B 8g computers with 32 gb SD cards. I installed the latest Raspbian Lite (64bit Bullseye) on all three RPi's. I kept getting errors in the k3s-ansible script. The Master would not start. I found this information in the Rancher k3s documents. I had to install iptables on all three systems and then run the following commands.
sudo iptables -F
sudo update-alternatives --set iptables /usr/sbin/iptables-legacy
sudo update-alternatives --set ip6tables /usr/sbin/ip6tables-legacy
sudo reboot
I also had to enable "cgroups" by adding "cgroup_memory=1 cgroup_enable=memory" to the end of the /boot/cmdline.txt file.
After rebooting all three RPi's, the k3s-ansible script worked correctly and the cluster is up and running.
It's the same with the current final of PiOS 64bt lite
The newest ansible version on github has most of these required fixes, but there are still a few small issues (if you want the ansible script to "just run"):
a) The current 64bit Raspian lite is not being detected as Raspian, so the fixes to cmdline.txt to help clean up /proc/cgroup are not being called. The fix (in the ansible script) is probably something like the addition of the following to roles/raspberypi/tasks/main.yml right after the "Raspbian buster" detection block:
- name: Set detected_distribution to Raspbian (ARM64 on Debian bullseye)
set_fact:
detected_distribution: Raspbian
when:
- ansible_facts.architecture is search("aarch64")
- raspberry_pi|default(false)
- ansible_facts.lsb.description|default("") is match("Debian.*bullseye")
b) That will get the critical roles/raspberrypi/tasks/prereq/Rasbian.yml to run, and it has some code that will quickly augment the cmdline.txt file. The one gotcha is that a reboot is necessary to really use the updated cmdline.txt file, and if you don't reboot asap... then the ansible script will fail later .
The fix is to be sure not merely "notify" a handler to reboot (and a reboot likely won't happen if/when the script later fails ), but rather to reboot more immediately. An example of a patch would then be ansible code in Raspbian.yml like:
- name: Activating cgroup support
lineinfile:
path: /boot/cmdline.txt
regexp: '^((?!.*\bcgroup_enable=cpuset cgroup_memory=1 cgroup_enable=memory\b).*)$'
line: '\1 cgroup_enable=cpuset cgroup_memory=1 cgroup_enable=memory'
backrefs: true
register: cmdline_text
- name: Reboot immediately if we edited the cmdline.txt file
reboot:
when: cmdline_text.changed
c) The next problem is the fact that iptables might not be in place. As you noted, you needed to install iptables. If that isn't done, then the call in Raspbian.yml to "flush the iptables" will fail with a command not found error.
You can't just skip that attempted flush (when iptables isn't installed), as it appears that you really do need iptables later, and in fact that is seemingly why the "alternatives" command is also present in Raspbian.yml. I'm not sure where in the yml files this should be done (and perhaps undone in reset??), but the minor hack of adding the following lines to Raspbian.yml before the attempted flush, seems to finish the play:
- name: Ensure that we have iptables (Raspian64 lite doesn't currently)
apt:
name: iptables
state: present
I'll try to send a pull request with the above changes for the owner to consider, but I thought a comment here could help folks as well (and maybe sooner).
Thanks, Jeff, for a very nice video and reference, and of course thanks to St0rmingBr4in for a nice ansible script.
(I had to work pretty hard to get a script together that would install microk8s cleanly... but it was a fun way to learn about ansible. The practice made it clearer how to help make suggestions for this ansible playbook).
One (or two?) more minor gotchas:
The version of k3s has moved forward in time since the github playbook was developed. As a result, when you get a copy of "kubectl" as suggested by Jeff, you'll probably get version 1.24 (or later?), rather than the 1.22 that you'll install on your bramble via the current referenced github playbook. K3s' version of kubectl refuses to allow versions that are "more than 1 apart" to talk to each other, so 1.22 and 1.24 are too different to play well (communicate). The fix is to update the playbook, modifying inventory/sample/group_vars/all.yml, to set the desired version to:
-k3s_version: v1.24.3+k3s1
With that, you are perchance almost set (to run the site.yml playbook)...
Alas, I couldn't get Jeff's proposed environment variable to work. When I tried:
export KUBECONFIG=~/.kube/config-turing-pi
kubectl get nodes
I got an error from kubectl telling me it couldn't find the config file, even though it CLEARLY was in exactly the place that the error message said it was :-/ (yes, it listed the fully qualified path to the config file, but claimed it wasn't to be found). It was picking up the environment variable, but it didn't help. I tried to relocate the file to a more "standard" place (mirroring what it was called on the server), and then tried:
export KUBECONFIG=~/.kube/config
kubectl get nodes
...but still no glory :-(. Then I tried a new shell without setting the environment variable, and kubectl.exe found it perfectly! It really likes ~/.kube/config. This could be a bug in kubectl.exe that I was running, or it could be a broader bug, but the moral is that (at least for me) it was better to put the configuration file in the "default" place, and let kubectl find it.
...which got me almost to where I wanted to be. My Pi bramble has a total of 7 nodes (each being an 8GB Pi 4), of which 3 I declared to be "master" nodes (via hosts.ini), and 4 I declared to be (worker) nodes.
The "kubectl get nodes" command listed ONLY one "control plane,master," along with 4 workers (with the ROLES column showing ), but I would *guess* that meant "worker."
Note that the ansible script did indeed (at times) work separately on the 3 wanna-be-master nodes, as well as working (at times) separately on the 4 worker nodes.
I was hoping to see ansible + k3s default into high availability mode (knowing that my ethernet switches and power setup would truly be single points of failure.. .but oh well).
Jeff: Did you ever try it with a more complete bramble?? Did you see than one master? Is this a K3s feature, leaving "other masters" invisible in standby? (I'd be surprised... but thought I'd ask).
Note that (in contrast to k3s) all microk8s configuration automagically drop into high availability mode whenever they have more than 2 nodes. Microk8s also shares duty equally among all nodes, meaning nodes can be both masters, and workers, and they should transition seamlessly as nodes fail etc.
I'm still on the fence about which one is best to play with... for instance hearing some assertions that k3s is faster.... but... Just today I read the "known problems" for k3s (https://rancher.com/docs/k3s/latest/en/known-issues/) and saw mention of the fact(?) that they don't play well with docker.
On a positive note, since I'm using ansible, it is really not-that-big-of-a-deal to to reformat my micro boot cards, and let ansible do its magic. I'll also get more ansible training as I make my k3s playbook better and better (Did you know that Raspbian 64 doesn't set up an /etc/environment file, which then leaves the snap installation with no where nice to land /snap/bin in the path that is picked up by ssh? ...but that's just another fix-up/install issues for ansible ;-) )
Hi all. I've run into a small issue where the ansible-playbook hangs when it reaches the k3s node "Enable and check K3s service" task. The same function runs fine for the master, it just stalls at the nodes. Any tips / tricks how to problem solve? I'm already using IP addresses in the hosts.ini file. Any help is much appreciated!
I'm not dead sure, but I think the critical fix is described in my earlier posting... but here is what I *think* will help your system to not hang.
[I could be mistaken... as I was hitting the "hang" in exactly the spot you mentioned when I used the Ubuntu 22 release... but after reading the K3s instructions, and their "compatibility" test page, I just switched to Ubuntu 20. I then also noticed (prior to running site.yml) that the Ubuntu playbook-customization appeared to have the same (potential) flaw as I saw with Raspbian.... so I inserted the patch below in the corresponding Ubuntu.yml file. ....and then the site.yml playbook seemed to work (not hang)... but I had already jumped back to Ubuntu 20 .]
The fix is to be sure not merely "notify" a handler to reboot (and a reboot likely won't happen if/when the script later fails ), but rather to reboot more immediately. An example of a patch would then be ansible code in Ubuntu.yml like:
- name: Activating cgroup support
lineinfile:
path: /boot/cmdline.txt
regexp: '^((?!.*\bcgroup_enable=cpuset cgroup_memory=1 cgroup_enable=memory\b).*)$'
line: '\1 cgroup_enable=cpuset cgroup_memory=1 cgroup_enable=memory'
backrefs: true
register: cmdline_text
- name: Reboot immediately if we edited the cmdline.txt file
reboot:
when: cmdline_text.changed
YMMV,
Jim
Fighting my way through the install with yet another flavor of OS, this time the 64 bit Ubuntu 22 version, I too got:
...ansible-playbook hangs when it reaches the k3s node "Enable and check K3s service" task.
Reading on the web, there is some "suggestion" about both Ubuntu version 21 and 22 needing a few more package installs to play well with version 22. Note that on the K3s site, only Ubuntu 20 is (currently) blessed. Take a look at:
https://github.com/k3s-io/k3s/issues/5443
Indeed, after I effectively performed the "sudo apt install linux-modules-extra-raspi" the ansible script ran to completion.
The nice-ish fix to the playbook is then to modify:
roles/raspberrypi/tasks/prereq/ubuntu.yml
adding the command:
- name: For Ubuntu 21 and 22, install linux-module-extra-raspi
apt:
name: "linux-modules-extra-raspi"
when: (ansible_distribution_major_version | int) > 20
Sorry my previous guess about your woes was probably mistaken. If you were/are using a newer Ubuntu, this may well be a solution.
Jim
One last trick, to better match Jeff's (excellent) philosophy of fleshing out the Playbook so that it can just rebuild the entire system.
His final comment was to manually(?) copy across the critical configuration via:
scp pirate@turing-master:~/.kube/config ~/.kube/config-turing-pi
Nicer is to add a single task, using the minimal host list containing the master node, and doing an Ansible "fetch" command. Be sure to start a fresh hosts list to enable the deed (with just one host), but other than that, it is pretty simple.
The critical elements (that I used, since I couldn't get the environment variable to be honored) are:
- name: Copy across config to enable local kubectl activity
fetch:
src: '~/.kube/config'
dest: '~/.kube/config'
flat: yes
If you've rebuilt with as many OS tries as I have... you'll be happy to give Ansible yet-one-more-task.
YMMV,
Jim
Thanks Jim for this! It has just saved me a lot of time :-)
Things have moved on a bit since this was written. The playbook now uses a YAML inventory, and the ansible user is required in that file. My issue is the resulting ~/.kube/config file only references 127.0.0.1 and so can't be used on my workstation without modification. I wonder if the install actually worked properly, or if this is normal. The output is:
paul@marler:~/ansible $ kubectl get nodes
NAME STATUS ROLES AGE VERSION
rpi5node03 Ready 28m v1.26.9+k3s1
rpi5node02 Ready 28m v1.26.9+k3s1
rpi5node01 Ready control-plane,master 29m v1.26.9+k3s1
paul@marler:~/ansible $