
OpenAI, which is only really open about consuming all the world's energy and half a trillion of our taxpayer dollars, just got rattled to its core.
Deepseek, a new AI startup run by a Chinese hedge fund, allegedly created a new open weights model called R1 that beats OpenAI's best model in every metric.
And they did it for $6 million, with GPUs that run at half the memory bandwidth of OpenAI's.
Besides the embarassment of a Chinese startup beating OpenAI using one percent of the resources (according to Deepseek), their model can 'distill' other models to make them run better on slower hardware.
Meaning a Raspberry Pi can run one of the best local Qwen AI models even better now.
OpenAI's entire moat is predicated on people not having access to the insane energy and GPU resources to train and run massive AI models.
But that moat disappears if everyone can buy a GPU and run a model that's good enough, for free, any time they want.
This blog post is an edited transcript of my video on the same topic, embedded below:
Raspberry Pi AI
But sensationalist headlines aren't telling you the full story.
The Raspberry Pi can technically run Deepseek R1... but it's not the same thing as Deepseek R1 671b, which is a four hundred gigabyte model.
That model (the one that actually beats ChatGPT), still requires a massive amount of GPU compute.
But the big difference is, assuming you have a few 3090s, you could run it at home. You don't have to pay OpenAI for the privilege of running their fancy models.
You can just install Ollama, download Deepseek, and play with it to your heart's content.
And even if you don't have a bunch of GPUs, you could technically still run Deepseek on any computer with enough RAM.
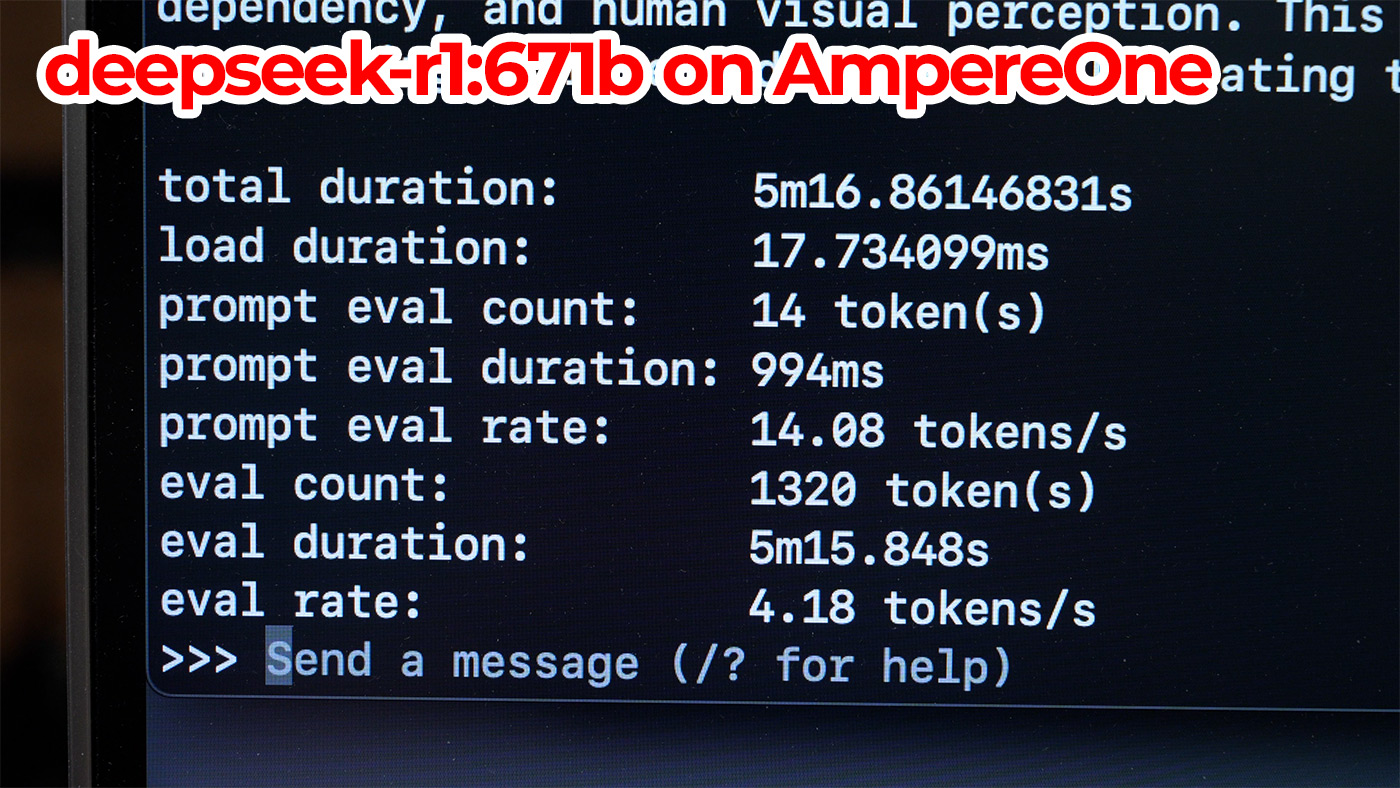
I tested Deepseek R1 671B using Ollama on the AmpereOne 192-core server with 512 GB of RAM, and it ran at just over 4 tokens per second. Which isn't crazy fast, but the AmpereOne won't set you back like $100,000, either!
Even though it's only using a few hundred watts—which is honestly pretty amazing—a noisy rackmount server isn't going to fit in everyone's living room.
A Pi could, though. So let's look at how the smaller 14b model runs on it:
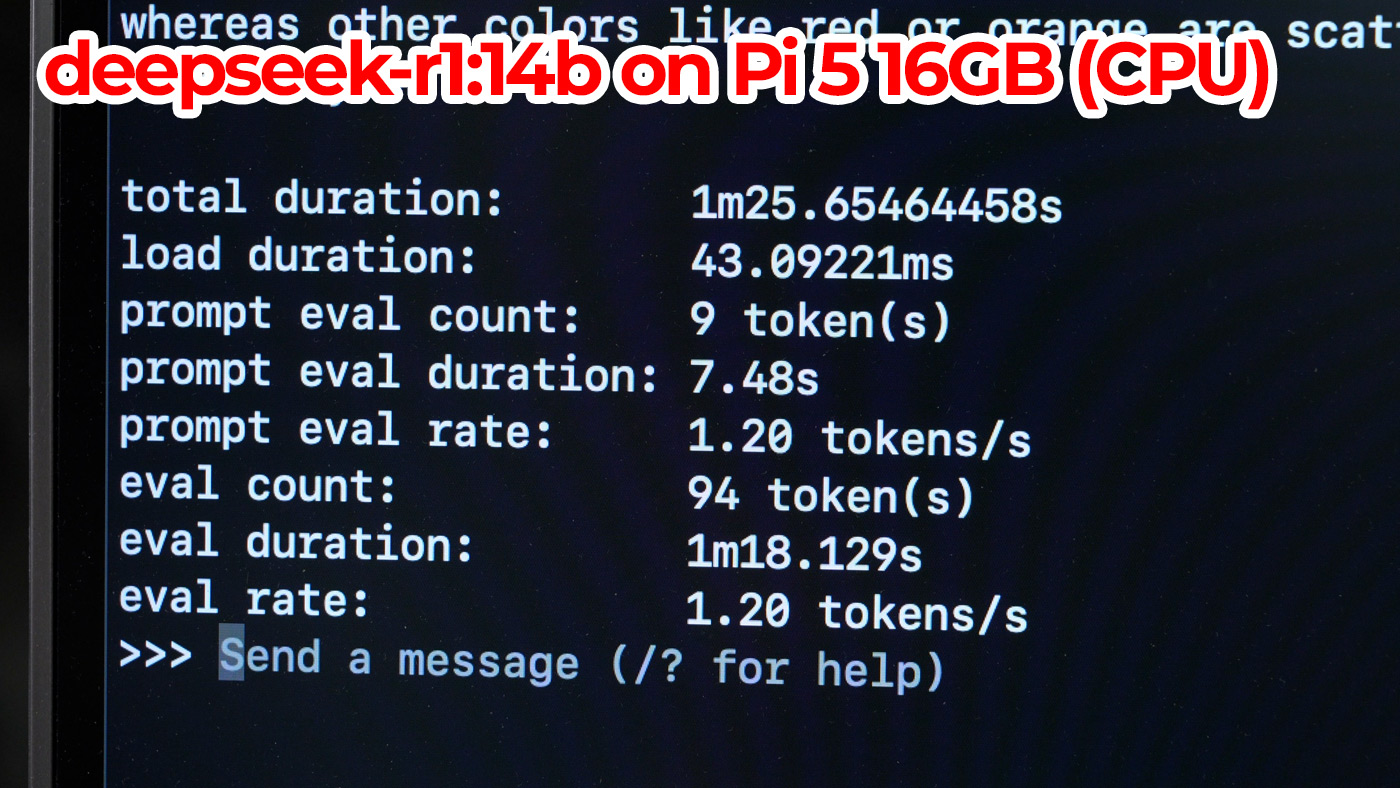
It's... definitely not gonna win any speed records. I got around 1.2 tokens per second.
It runs, but if you want a chatbot for rubber duck debugging, or to give you a few ideas for your next blog post title, this isn't fun.
Raspberry Pi GPU AI
But we can speed things up. A lot. All we need is an external graphics card, because GPUs and the VRAM on them are faster than CPUs and system memory.

I have this setup I've been testing with an AMD W7700 graphics card. It has 16 gigs of speedy VRAM, and as long as it can fit the whole AI model, it should be much faster:
| model | size | params | backend | ngl | test | t/s |
|---|---|---|---|---|---|---|
| qwen2 14B Q4_K - Medium | 8.37 GiB | 14.77 B | Vulkan | 99 | pp512 | 193.31 ± 0.35 |
| qwen2 14B Q4_K - Medium | 8.37 GiB | 14.77 B | Vulkan | 99 | pp4096 | 168.01 ± 0.25 |
| qwen2 14B Q4_K - Medium | 8.37 GiB | 14.77 B | Vulkan | 99 | tg128 | 24.41 ± 0.24 |
| qwen2 14B Q4_K - Medium | 8.37 GiB | 14.77 B | Vulkan | 99 | pp4096+tg128 | 54.26 ± 0.92 |
llama-bench reports 24 to 54 tokens per second, and this GPU isn't even targeted at LLMs—you can go a lot faster. For full test results, check out my ollama-benchmark repo: Test Deepseek R1 Qwen 14B on Pi 5 with AMD W7700.
Conclusion
AI is still in a massive bubble. Nvidia just lost more than half a trillion dollars in value in one day after Deepseek was launched.
But their stock price is still 8x higher than it was in 2023, and it's not like anyone's hyping up AI any less now.
The one good takeaway, I think, is people might realize we don't need to devote more than half the world's energy resources or set up a Dyson sphere around the sun, just to help computers solve trillions of multiplication problems to spit out another thousand mediocre web apps.
The other takeaway is that there's new confusion in AI models over who, precisely, is Winnie the Pooh.
Comments
What tool do you use for benchmarking the models?
What about the AI pi hats how do they handle compared to the gpu?
Jeff, I really expected you to do the research before making a video jumping on a hype train, like you used to do.
What you are running is not R1. In fact, there are no R1 besides the full 671B. What you ran there were qwens, distilled by R1, but not MoE, not reasoning, and nothing special because the base model is the same qwen.
After seeing all others claim they ran R1 on their mother's Nokia I really thought you wouldn't make the mistake of confusing the R1 with these distilled models for clicks but there you are.
In the blog post:
Note that Ollama labels all the distilled models as "deepseek-r1"
Yep, and the community is furious about it because Ollama chooses to join the hype and enjoys being introduced as "the easiest way to run R1 on any device".
You could have been the one that debunked the manipulative naming scheme. I am not sure if Is it too much to ask for someone that possesses the knowledge like you to inform the viewers better.
That's exactly why I said:
You didn't read the article?
Hi Jeff, quick question after I saw your tests with a rpi5 with deepseek, will you maybe also do some test with e.g. a Mac mini m4 or a mini pc. I think if this will be efficient a lot of people will maybe think to use something like this for ha support e.g. for voice to text and local ai. I would be very interested in what is maybe a cheap setup which is not to slow.
So cool! How would this behave with a cluster of lets say 10 raspberry pis? Would you have an idea?
Hmm, OpenAI or Chinese hedge fund? Pick your poison I guess.
You can run it 100% off line, 100% and it doesn't support the CCP in anyway.
OpenAI just scammed billions of dollars from the government to build data centers we don't really need. Yea I'm not going to fund a conman for a worse product when a free model exists.
Don't forget they sucked up practically all public copyrighted data (including this blog) to train their models. I don't have sympathy for OpenAI.
The beautiful irony of OpenAI complaining that DeepSeek might have scraped ChatGPT was something to savor.
I have 12 Azulle Access3 mini pc sticks. They are running the Intel N4100 with 4GB RAM and 32GB eMMC (with an available mSD slot). I have been thinking about what to do with all these devices. I know Linux can be installed on them, so what are your thoughts on trying to build a cluster of these and seeing if I can run this LLM on the cluster? Im not new to Linux, but I have also never messed around with clustering at all.
Do you have access to the official Raspberry Pi AI kit (Raspberry Pi M.2 HAT+ with a Hailo AI acceleration module)? If so, can you add a new benchmark using this setup to compare the token rate difference?
The current ai kit is for images a new one is supposedly coming q1 2025 that will be for llms. I am hoping Jeff gets an early one for testing.
I tried the 1.5B and 7B models on my Pi-5 8gb, but they don't respond with any answers. The other ollama models work fine. Not sure what's going on.
I just lol'ed, I watched your video yesterday, and my google feed just fed me this. While reading I kept going "why is is this so similar?", and then looked at what I was fed 😂
At least the algorithm is working
It's like "You liked it once, and you will like it again!"
Any progress on Rcom support on arm or pi specific kernels?
You can also try to create a cluster from Rasberry Pi devices and run this: https://github.com/b4rtaz/distributed-llama