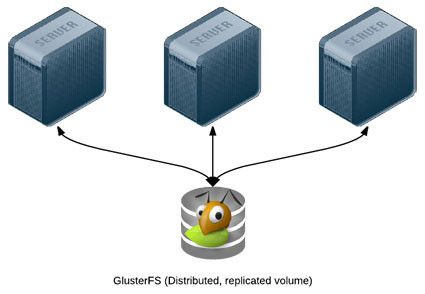
Simple GlusterFS Setup with Ansible
The following is an excerpt from Chapter 8 of Ansible for DevOps, a book on Ansible by Jeff Geerling.
Modern infrastructure often involves some amount of horizontal scaling; instead of having one giant server, with one storage volume, one database, one application instance, etc., most apps use two, four, ten, or dozens of servers.
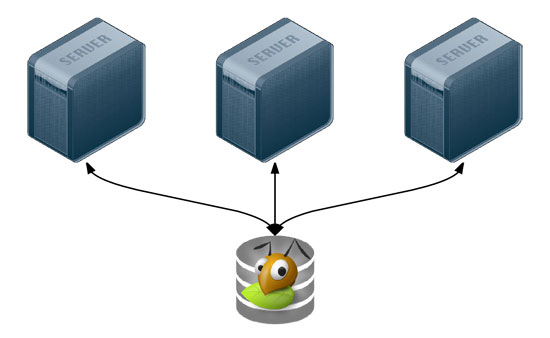
Many applications can be scaled horizontally with ease, but what happens when you need shared resources, like files, application code, or other transient data, to be shared on all the servers? And how do you have this data scale out with your infrastructure, in a fast but reliable way? There are many different approaches to synchronizing or distributing files across servers: