I've long used Munin for basic resource monitoring on a huge variety of servers. It's simple, reliable, easy to configure, and besides the fact that it uses Perl for plugins, there's not much against it!
Last week, I got a notice from my 'low end box' VPS provider that my Munin server—which is aggregating data from about 50 other servers—had high IOPS and would be shut down if I didn't get it back into an allowed threshold. Most low end VPSes run things like static HTML websites, so disk IO is very low on average. I checked my Munin instance, and sure enough, it was constantly churning through around 50 iops. For a low end server, this can cause high iowait for other tenants of the same server, so I can understand why hosting providers don't want applications on their shared servers doing a lot of constant disk I/O.
Using iotop, I could see the munin-update processes were spending a lot of time writing to disk. And munin's own diskstats_iops plugin showed the same:
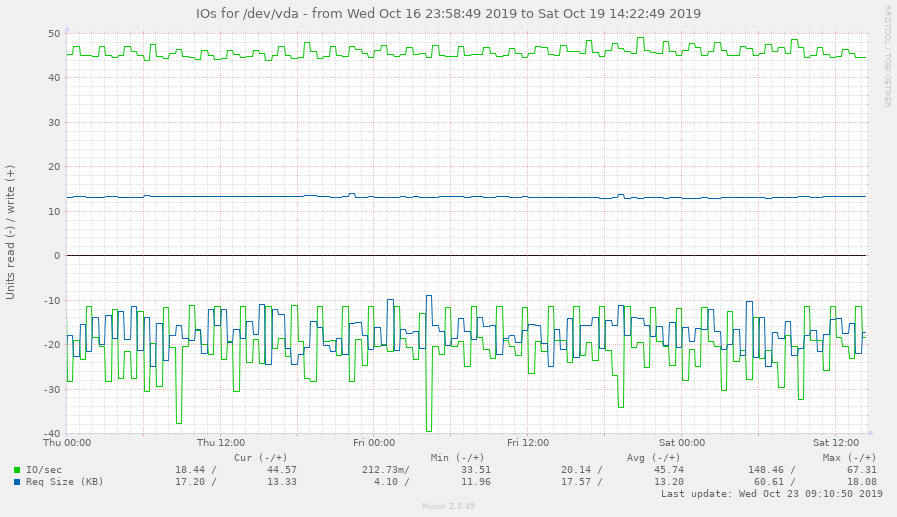
Reading up on ways to reduce overall disk usage in Munin, I discovered this article on raymii.org, which linked to the following documentation page: Scaling the munin master with rrdcached.
I am running this server on CentOS 7 currently, so I used systemd to manage the rrdcached daemon. Here's how I did it:
First, create a /usr/lib/systemd/system/rrdcached.service unit file. This file tells systemd how to start and run rrdcached in the background:
[Unit]
Description=RRDCacheD for Munin
After=network.service
[Service]
Type=forking
PIDFile=/run/munin/rrdcached.pid
User=munin
ExecStart=/usr/bin/rrdcached -p /run/munin/rrdcached.pid -B -b /var/lib/munin/ -F -j /var/lib/munin/rrdcached/ -m 0660 -l unix:/run/munin/rrdcached.sock -w 1800 -z 1800 -f 3600
[Install]
WantedBy=multi-user.targetMake sure systemd knows about this new service:
systemctl daemon-reload
Then start the service and verify it's loaded and active:
systemctl start rrdcached
systemctl status rrdcached
(Note that if you have rrdtool installed on CentOS (which you should as it is installed with munin), it should already have rrdcached available in /usr/bin.)
If you are using the cgi graphing strategy (highly recommended unless people are looking at the munin graphs all day and night and you want them pre-rendered), make sure the rrdcached UNIX socket file is readable by the webserver (Apache, in this case):
sudo chgrp apache /run/munin/rrdcached.sock
Finally, to make sure munin is using rrdcached to queue up writes, edit /etc/munin/munin.conf and make sure the following line is present:
rrdcached_socket /run/munin/rrdcached.sock
Now, after the next munin cron run, you should see your disk IO start to die down. If you're seeing empty graphs or it looks like something's not right, tail the munin-update.log file in /var/log/munin and see what it's saying. Here's my iops graph now, a few hours after implementing the change:
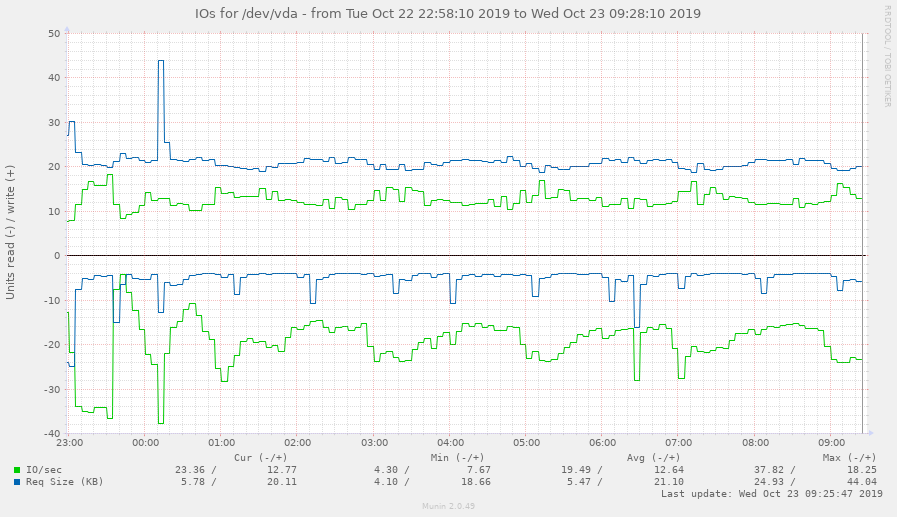
The average iops went down from 45 to 12, while the req size went up slightly. This is a good thing, as it means I'm writing larger chunks of data less frequently—much better for the disk and for shared tenants dealing with iowait on this server hardware.
Two other changes which can further reduce disk IO during munin runs include:
- Using the cgi graphing strategy (where graphs are generated when a user visits the Munin frontend, instead of being regenerated on every single munin cron run). I am already doing this, so no further gains here.
- Writing html and graphs to a tempfs volume instead of the main system disk. I haven't done this yet, but raymii's article shows how to do it if you're interested.
Comments
How many gigs does this low end box have?
Changing the group of the UNIX socket to the web server's group breaks munin-update, as it can no longer write to the socket.